
Pipedream!
At work we often create logical abstraction layers to connect one platform to one or more data sources, or other platforms. Pipedream is an interesting cloud based services which allows you to create 'workflows' hosted by pipedream.
A pipedream workflow takes some trigger (which may include some data), follows 'steps' as defined by the author to get more data, transform data, send to apps like airtable, slack, email, netlify, paypal, twillio, and much more.
The Case for Abstraction
While pipedream might look like something that is handy for connecting to apps and services without having to write a bunch of code, there is a underlying reason/purpose you may want to consider here. Basically it is decoupling. When integrating one thing to another, particularly if you manage a lot of integrations, you are essentially hard coding that integration. If you find yourself replacing a platform with 100 integrations, not only do you have to replace that platform but you also have to go update the 'other side' of each of those integrations. An abstraction layer in between which allows you to integrate with that service bus and have 100 integrations with the bus allows you to manage a smaller set of integrations when making a change (so long as you don't change your bus!)
Design Patterns
When creating an abstraction layer, there is a lot to think about. Here are three pretty high level ideas to noodle on first:
- State. Typically, we try to have a stateless (transactional) middleware which has the job of abstracting an interface, and potentially translating (SOAP to REST for example), transforming (manipulate), or even doing some business logic. Try to separate the components that stores original data (stateful) with the components that transactionally deal with data (stateless.) If you need maintain state, then:
- Think about the 'owner' of the state of that datapoint. When anyone in the organization thinks about where they would go to find that datapoint, and more importantly, where they would go if there was disagreement between systems about that datapoint. That is the state owner. Whenever possible reference the state owner, instead of duplicating the datapoint. If you do have to (caching for performance reasons, for instance) make sure you've got some sort of TTL on the copy that is consistent with the purpose of the duplication of the data
- If you have 'original' data... That is you are creating new data that has never been stored before, and you need to maintain the state, then you should be using something stateful like a document store, database, block device, or whatever.
- Parameterize. Plan ahead! You may be building something that has only a single use case, but if you are intentional to not hard code data, methods, or business logic, but instead allow that to be specified via a parameter, you've made your code much more reuseable for future use cases. If you enjoy more technical reading, consider reading up on some specific design patterns in this area: dependency injection, strategy, template method, abstract factory, and factory method. (keep in mind that these patterns are often in the context of OOP, but they are behavioral patterns that you can apply similar thinking to systems, and how you build anything, really.)
- Model. There is a natural tendency to think about 'the data model' whether it is in JSON, a RDBMS, or whatever, in the format that it originated in. That is to say, if I wanted to get data from the API of some monolithic platform designed to do something specific, you may think "the data I want is buried in this tree, I'll just xpath down to the bits I want and move on. It is more work up front, but I'd encourage you to think about modeling the data the way you think about it, rather than keeping it in the shape that is good for some big platform that thinks about it differently. In particular, if you're building software for an organization, organize the data the way they think about and talk about the data. This will make life much easier later, and will also strengthen the abstraction layer as a true abstraction. If any platform breaks protocol or you have to replace it, it'll be much easier to think about how to conform a new platform to 'how you think about the business' than 'how it relates to another platform'. What I've noticed is maturity evolution with regards to how we model data in an abstraction layer:
- don't change the model. Just grab the parts we want and pass it along in a similar structure.
- restructure the model for a specific use case. Convert from something platform specific to a model that fits the need of specific endpoint.
- restructure the model for a business domain. Every model is a sub-model of a larger model that serves the entire domain. sub-models from a specific use case can be unified with other sub-models and relationships between them are consistent and unambiguous.
Learning How Pipedream Works
OK, enough theory. Let's play with pipedream and see how it works. First, I started with this video to help get a handle on what it is and how it works:
Creating a Workflow
Next, I create a pipedream account, and start a project and create a http trigger as the initial trigger:
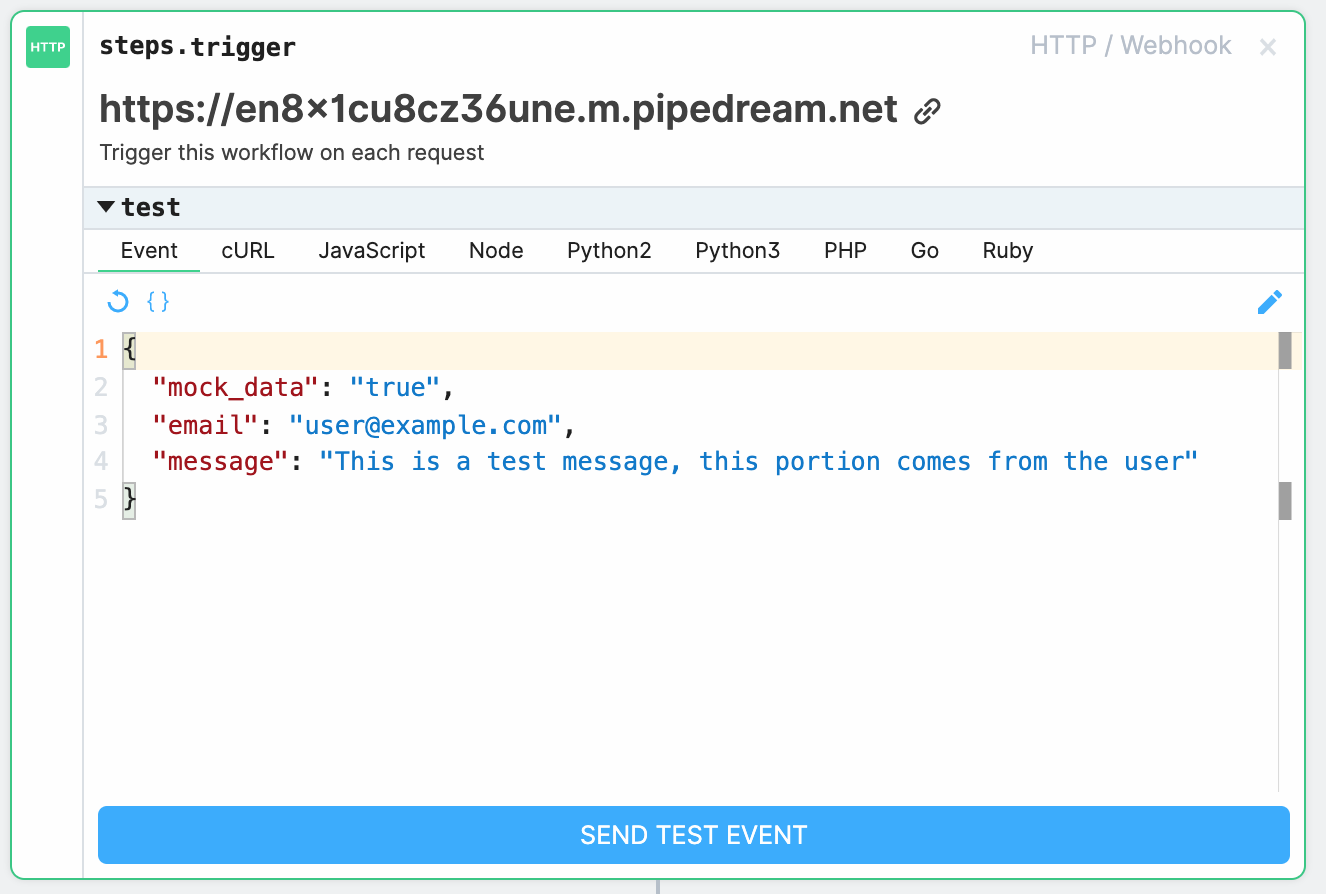
Then we create a 'email me' step, and enter in some of the parameters specified in the http trigger:
{kind=link}
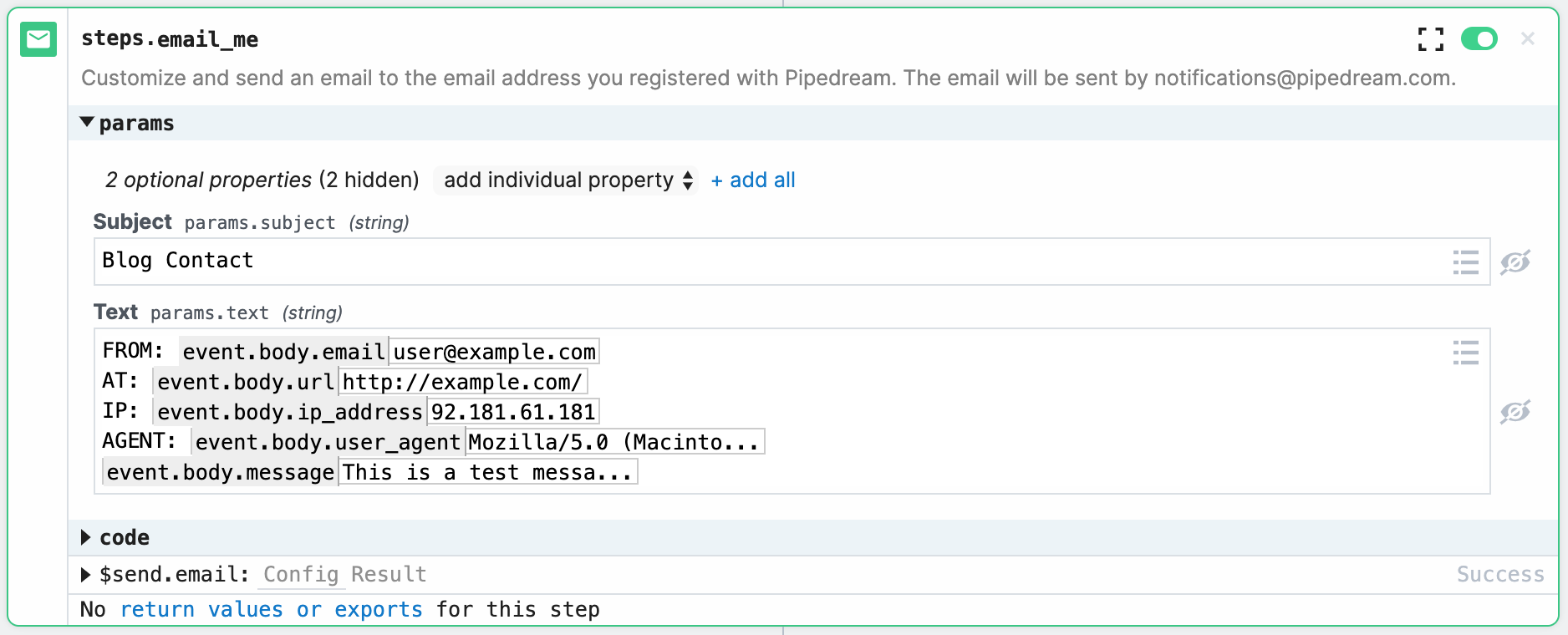
Push this to the pipedream environment, and it creates a webhook listener for me. OK, if I look at the http step, under 'test', I see that I can 'send to test environment' which will actually test the endpoint. Click on it, and... an email shows up! That was easy!
Also in the 'test' area of the trigger, is some helpful code examples showing me how to access the endpoint:
curl -d '{
"mock_data": "true",
"ip_address": "92.181.61.181",
"email": "user@example.com",
"message": "This is a test message, this portion comes from the user",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_4) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.100 Safari/534.30",
"url": "http://example.com/"
}' \
-H "Content-Type: application/json" \
https://e.m.pipedream.net
const headers = new Headers()
headers.append("Content-Type", "application/json")
const body = {
"mock_data": "true",
"ip_address": "92.181.61.181",
"email": "user@example.com",
"message": "This is a test message, this portion comes from the user",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_4) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.100 Safari/534.30",
"url": "http://example.com/"
}
const options = {
method: "POST",
headers,
mode: "cors",
body: JSON.stringify(body),
}
fetch("https://e.m.pipedream.net", options)
OK, so... I basically need to get some stuff from the user, place it into a key value array, and then fetch the endpoint via POST. OK... I think I can do that... maybe. Let's try!
Build the front-end
OK... Last step is to build a front end form that will call this endpoint. For this, I head over to jsfiddle to play with it until I get it where I like it.
This seems to work ok:
<h2>Contact Us</h2>
<form action="https://e.m.pipedream.net" method="post" target="_top">
Email:<input name="email" type="text" />
Comments:<textarea name="message"></textarea>
<input type="submit" value="Submit" />
</form>
Example Form
An actual working contact form. This form calls out to pipedream and sends the user data. Give it a try, I'll get your message via email!